Tracing the evolutionary history of languages
Written on February 5th, 2025 by Gonzalo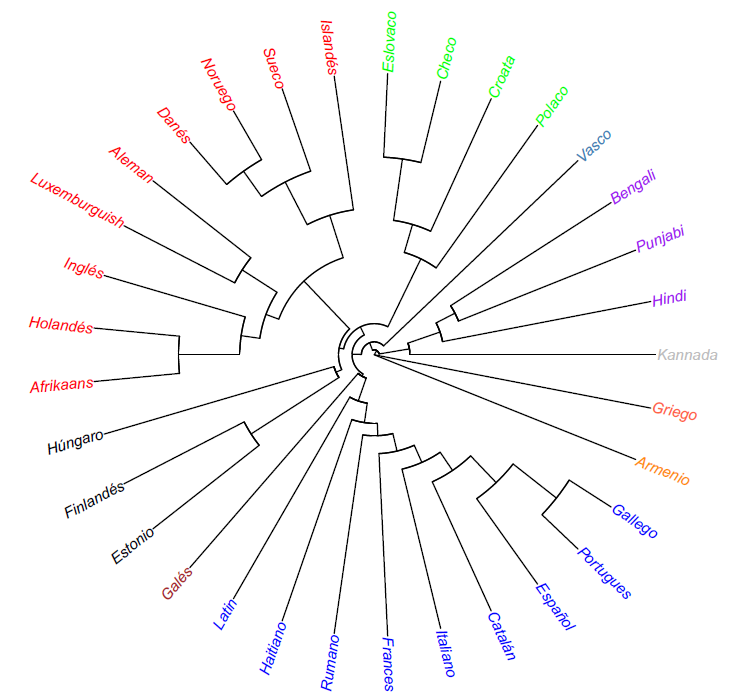
A simple method for comparing the historical evolution of languages.
In 2015 I had the chance to travel through northern Europe, Russia, Mongolia, South Korea and Japan. During my trip one thing that’s caught my attention was the diverse of languages and the historical components that lead to the evolution of all those diverse ways of communication. I got aware of the linguistic theory and its classifications. German, English, Danish, Norwegian and Swedish all come from the Germanic line, a branch of the Indo-European languages. The Finnish and the Estonian are closely related languages and despite Finland and Estonia are in the same geographic region as Sweden and Norway, Finnish and Estonian came from a whole different branch not even related to Indo-European Languages: they come from the Uralic languages. During my visit to Russia I learnt the Cyrillic alphabet and understood the deep connections between the Slavic culture and how the Cyrillic was forged. Then after I got impressed how the Soviet Union introduced the Cyrillic alphabet in the Mongol language and how this resemblance the case in which the Arabs introduced the Arabic Alphabet to the Farsi (or Persian). Neither the Farsi and the Arabic nor the Russian and the Mongol are related languages, however it’s amazing to see how the historical forces play a key role by shaping the way we communicate. Anyways, after my long trip I became thoughtful regarding the historical evolution of languages and I took some tools from my background as a biochemist. Indeed, for comparing two related (or not-that-related) species, biological scientists use clustering algorithms based on the similarities or dissimilarities of genetic code.
Inspired on the idea of bioinformatics, I assembled 100 common concepts based on what linguists call the Swadesh List. This list is set of concepts compiled for historical-comparative linguistics studies. It was named after the American linguist Morris Swadesh.
For 27 languages, we (Zoe Huang and Gonzalo Oyanedel, 2022) built dendrograms based on 3 “challenges” (Swadesh list, Lord’s Prayer and Starman by David Bowie) and 3 algorithms (Levenshtein, Needlman Wunsch and Damerau-Levenshtein). Below you can see the resulting dendrograms:
- Levenshtein, Swadesh List
- Levenshtein, Lord’s Prayer
- Levenshtein, Starman
- Damerau–Levenshtein, Swadesh List
- Damerau–Levenshtein, Lord’s Prayer
- Damerau–Levenshtein, Starman
- NWL, Swadesh List
- NWL, Lord’s Prayer
- NWL, Starman
Do it by yourself!
Here the repo and the data to perform these analysis!
